AI Image Maker
请登录后生成图片

"A [SUBJECT] is crouching on the beach, lifting a wave like a carpet to reveal a [OBJECT] lying underneath deep inside. The ocean is calm with a clear blue sky in the background. The scene creates a clever illusion, in a surreal manner, with the wave being lifted as if it is a tangible object"

统一文本与视觉理解
GPT-4o Image 模型(也称为 GPT-Image-1)是 OpenAI 最新的 AI 图像生成模型。与传统扩散模型不同,它统一了文本和视觉理解能力,允许开发者直接通过自然语言提示生成高分辨率、上下文感知的图像。无论是应用界面、营销视觉素材还是 AI 设计工具,它都能提供出色的精确度、构图控制和视觉细节。
GPT-4o Image 实际应用案例
宫崎骏吉卜力风格艺术
借助 GPT-4o Image 模型,用户可以生成受吉卜力工作室标志性风格启发的视觉作品。通过提供描述性提示词,GPT-Image-1 模型能产出具备吉卜力电影特有的奇幻细腻美学的图像,助力概念艺术和创意项目。

产品可视化与展示
利用 GPT-4o 图像生成模型,企业可以创建逼真的产品样机和展示图。通过文字描述生成高质量产品图像,使企业无需实物原型即可展示产品。

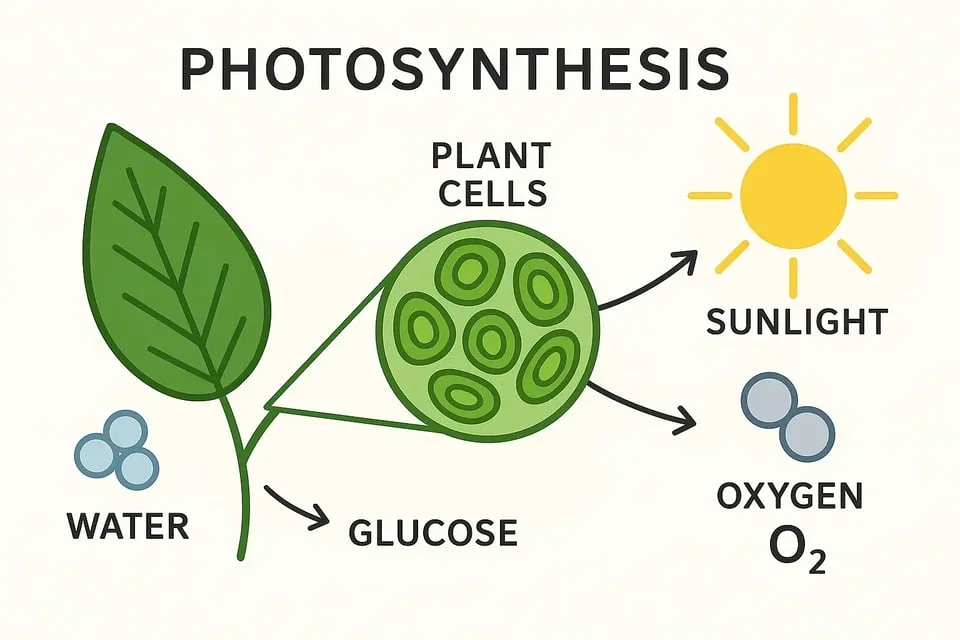
信息图表与图形设计
借助深度上下文理解能力,GPT-4o Image 模型可以生成清晰传达复杂数据的信息化视觉图和图表。利用模型的世界知识,用户可以生成既准确又视觉吸引人的教育信息图或商业图表。
一致的角色与资产设计
GPT-4o 图像生成模型帮助开发者和游戏美术师在多个场景中保持角色和风格的一致性。通过指定属性和风格,模型可以生成详细的角色图像,确保不同场景和迭代之间的统一性。

GPT-4o Image 核心功能
文生图与图生图
GPT-4o Image 模型(由 GPT-Image-1 驱动)同时支持文生图和图生图工作流。开发者可以从简单的文字提示创建高分辨率视觉内容,或通过智能编辑和变体功能优化现有图像。
精准的图像内文字渲染
GPT-4o Image 模型的突出改进之一是能够在生成的图像中清晰渲染文字。无论是标牌、UI 元素还是产品标签,都能确保可读且上下文正确的文字放置——解决了 AI 图像生成中的长期难题。
精确的指令遵循
GPT-4o Image 模型擅长解读复杂提示词并遵循细微指令。它能理解物体之间的关系、光影和构图,确保每张生成的图像都与用户意图紧密吻合。
世界知识与上下文感知
基于 OpenAI 的多模态基础,GPT-4o Image 将深度世界知识和上下文理解融入每次生成。它能识别真实世界的物体、文化元素和场景逻辑,生成自然、真实且上下文准确的视觉内容。
多样化的艺术与视觉风格
从照片级写实渲染到吉卜力风格的动漫插画,GPT-4o Image 模型支持广泛的艺术方向。开发者可以轻松调整色调、光影和视觉美学,以匹配品牌标识或创意方向。
一致的角色与风格
GPT-4o Image 模型在多次生成中保持出色的角色和风格一致性。无论是设计品牌头像、常驻角色还是连续场景,模型都能保留关键视觉特征,确保创意工作流中输出的连贯性。